The Best AI Engineers = Reliability Engineers. Here’s How to Build Like One

A car dealership chatbot sold a Chevy for $1. A lawyer cited fake cases in court using ChatGPT. These aren’t funny anecdotes - they’re what happens when teams chase AI capability without designing for AI reliability.
Here’s the truth we need to say more often: LLMs are super capable - but also wildly unreliable. The difference between a flashy demo and a production-ready AI system is always reliability.
Let’s talk about how to build for it.
The AI Capability Rush — and the Reliability Cliff
With 68% of executives planning to invest up to $250M in AI this year, teams are under pressure to ship. The result? Demos that impress, systems that break. Most teams don’t lack ambition - they lack the operational muscle and experience to build systems that hold up under real-world conditions.
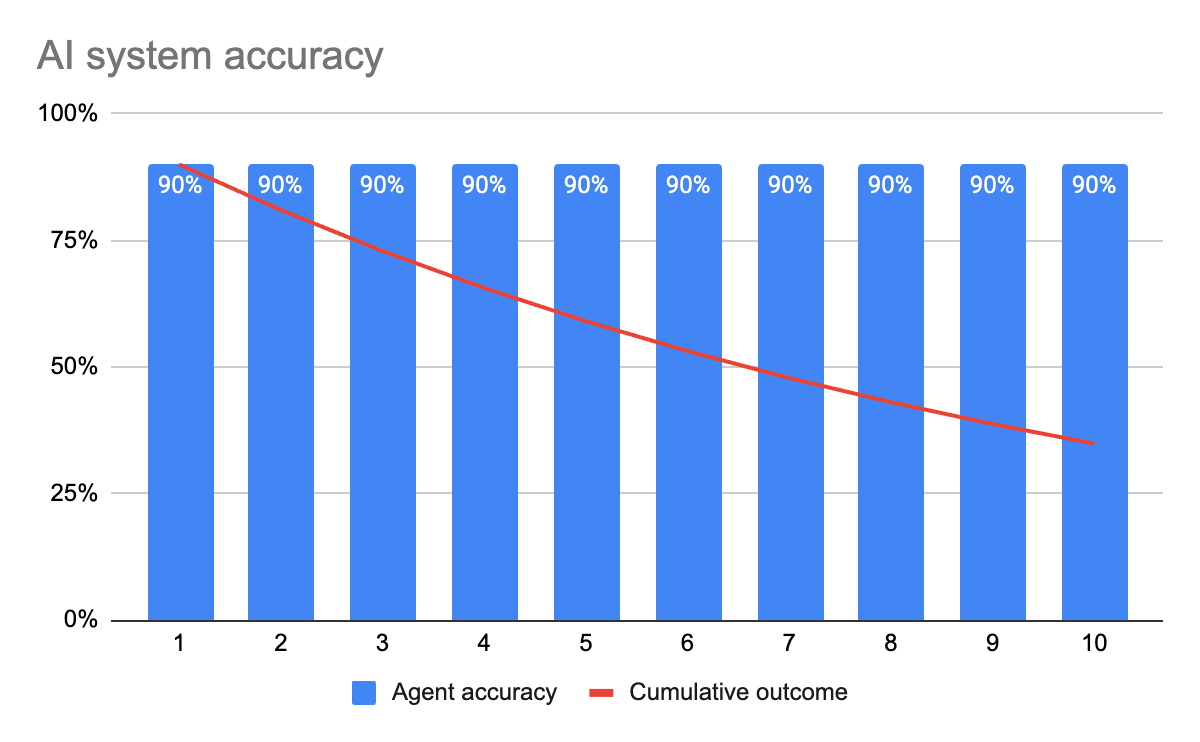
Let’s put numbers to that. Suppose your AI system has 10 steps: authenticate → fetch data → analyze → summarize → generate → and so on.
Each step has a 90% success rate. Sounds fine, right?
Until it doesn’t.
Your end-to-end reliability drops to just 35%.
Why? Because errors compound. One unreliable component can poison the entire system.
Browser-based agents like Manus or GPT Operator look slick in demos - until they have to scrape multiple pages or maintain task state. That’s why reliable systems need checkpoints: reset context, log every action, and validate outputs at every step.
Coding agents tend to perform better - not because they’re smarter, but because their outputs can be tested.
The pattern is clear: without validation at each step, even capable AI crumbles.
Authentication and Evaluation: The Foundation of Trust
Authentication isn’t a one-time checkbox - it’s a recurring process.
In agent systems where LLMs access user data, authentication failures create outsized risks. Each step that accesses data should have its own authentication verification - don't assume that because step 1 was authenticated, step 5 is still secure.
You don’t want to be the team that lets an LLM loose on customer data unchecked. Every action should re-auth, log its access, and be independently evaluated.
Trust the system not because it worked once - but because every step is verified, every time.
Binary evaluations make improvement possible
Subjective scoring doesn’t scale. Five people rating an output from 1–10 won’t give you actionable feedback. Replace it with binary criteria:
Does it directly answer the user’s question? (Yes/No)
Does it contain factual errors or hallucinations? (Yes/No)
Is it compliant with our safety guidelines? (Yes/No)
Does it match our brand voice? (Yes/No)
“3.3 vs. 4.7” means nothing. “Pass vs. Fail” tells you what to fix.
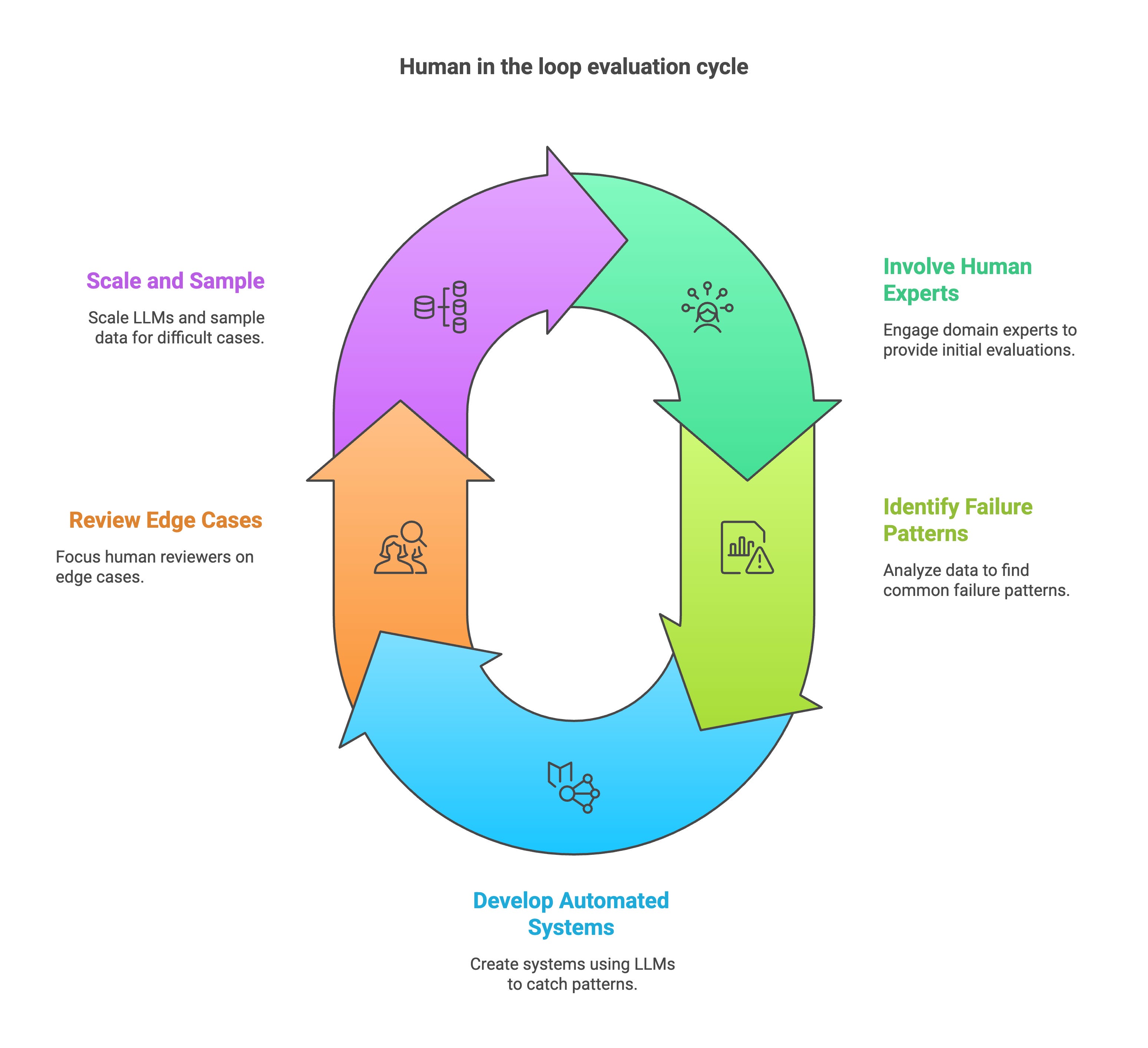
Human-in-the-Loop: Your Feedback Engine
Start your evaluation process with humans, ideally domain experts. Get real comments, identify common failure patterns, and only then begin automating parts of the evaluation. Don’t rush to replace people too soon. You’ll miss nuance, edge cases, and critical early insights.
This human-in-the-loop cycle is your feedback engine:
Experts provide ground-truth reviews
Patterns guide automation
Humans handle edge cases
Systems improve in a loop
Benchmarks Don’t Matter. Your Evaluation Framework Does
Don’t get distracted by flashy benchmark scores like MMLU, MATH, GPQA, HumanEval, or SimpleQA - they don’t predict how your model will perform in your real-world use case.
Every AI system needs a custom evaluation framework, tuned to its specific workflows and failure points. That’s why 80% of AI projects fail, even with strong third-party metrics. And you don’t need complex tools to get started - a simple spreadsheet tracking outputs, failures, and reliability step by step is often more valuable than any enterprise-grade platform. As you learn more, upgrade your tools - but never confuse sophistication with impact. Clarity beats complexity. Don’t over-engineer.
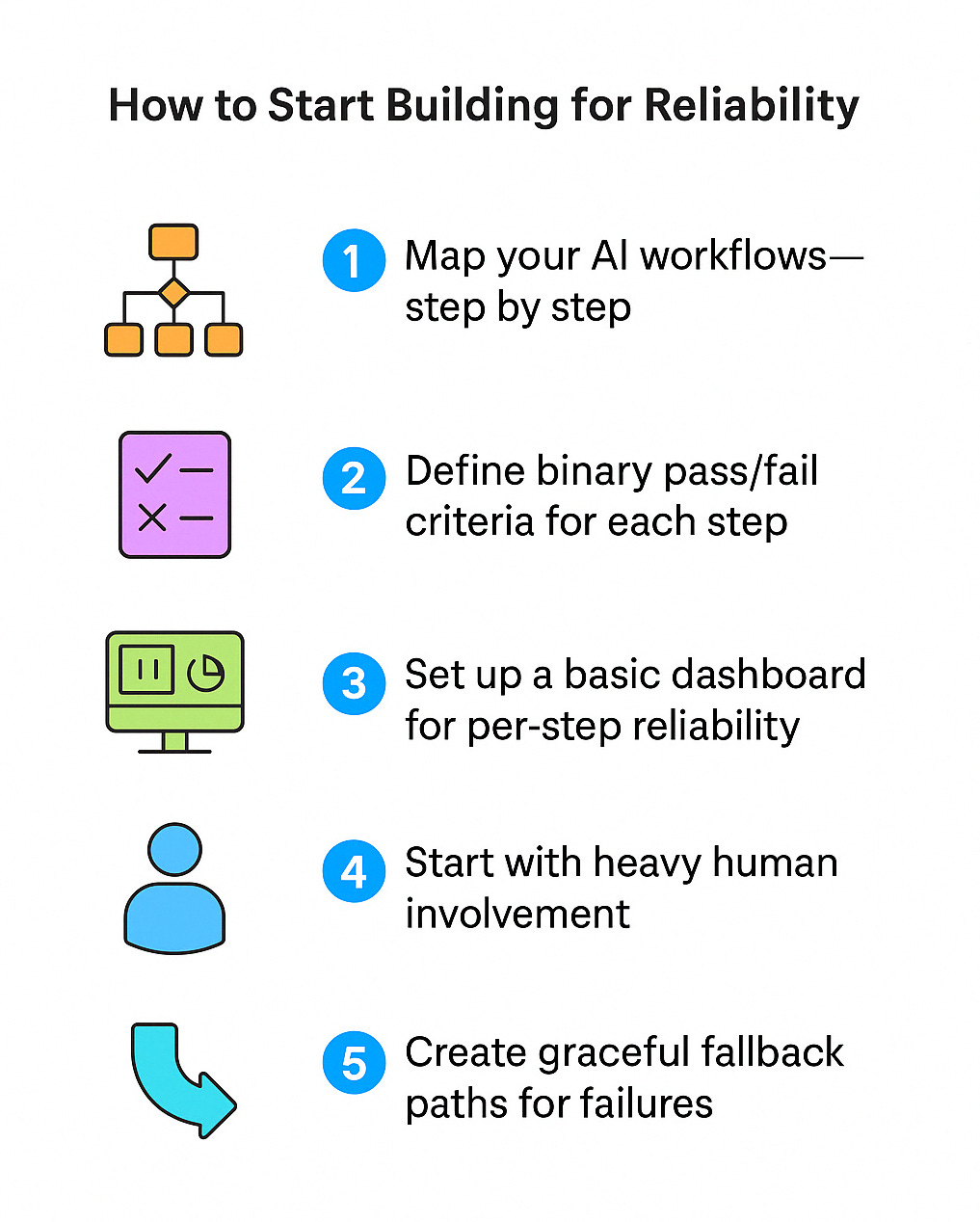
How to Start Building for Reliability
Map your AI workflows step by step
Define binary pass/fail criteria for each step
Set up a basic dashboard for per-step reliability
Start with heavy human involvement
Create graceful fallback paths for failures
Reliability isn’t a feature. It’s the product.
And it’s what makes your AI usable, safe, and trustworthy in the real world.
In my next post, I’ll break down how I built a lightweight email labeling tool - and the simple steps I took to make the data reliable from day one.
Hit subscribe to get the walkthrough.